ゲームサイトの過去データを保存し、オフラインで閲覧できるようにしたい場合、Wayback Machine からデータを取得して整理する方法を紹介します。
1. Wayback Machine とは?
Wayback Machine は、インターネット上のウェブページを定期的にアーカイブするサービスです。これを利用することで、過去のウェブサイトを閲覧し、保存することができます。

Wayback Machine
web.archive.org
2. 取得するサイト
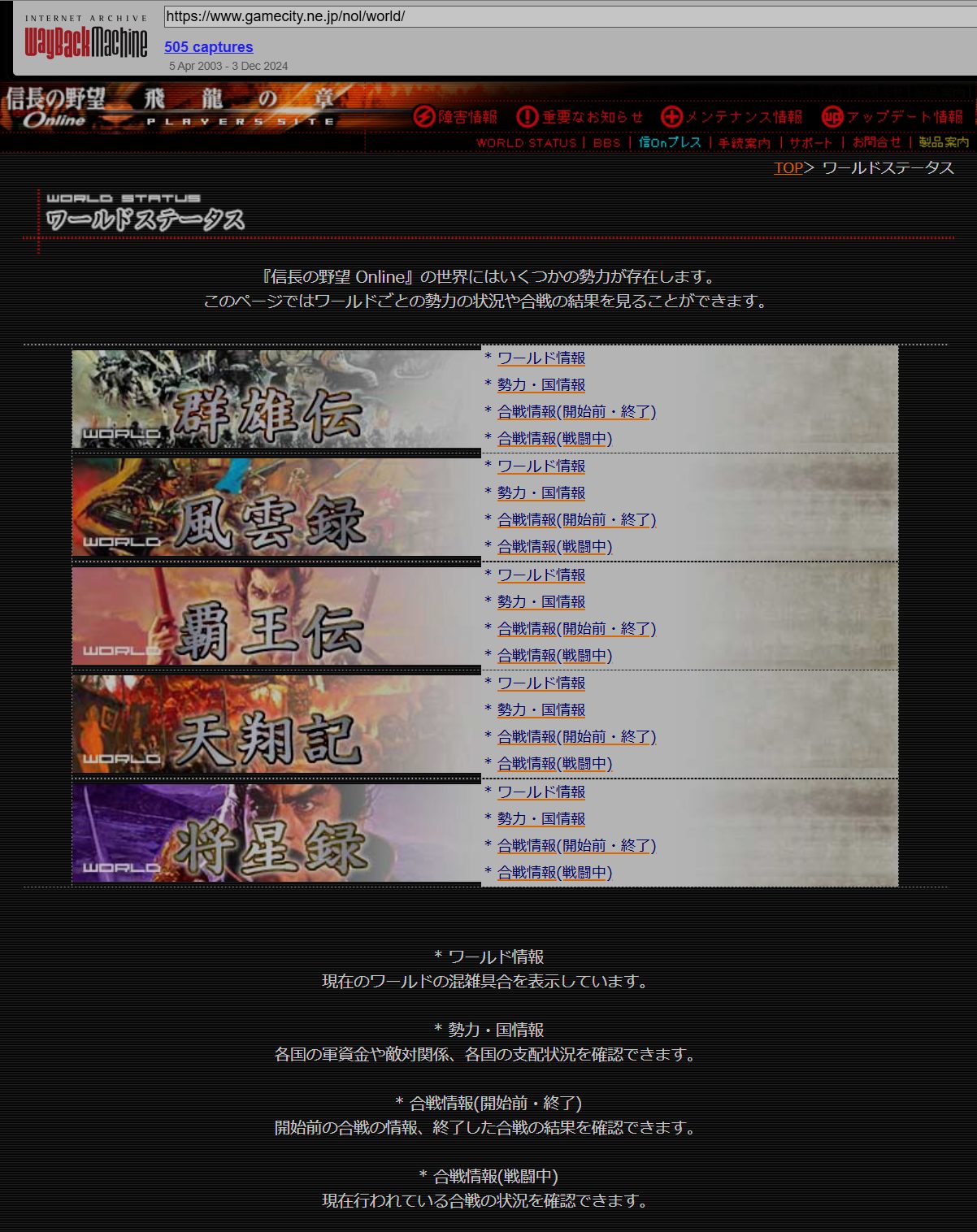
今回、取得するのは「信長の野望 Online」の公式サイトの一部:
https://www.gamecity.ne.jp/nol/world/
過去に保存されたデータをすべてダウンロードし、日付ごとにフォルダに整理して保存します。
3. 必要なツール
取得に使用するツールは以下の通り:
wget(ウェブページをダウンロードするコマンド)jq(JSON データを扱うツール)
Linux では以下のコマンドでインストールできます:
sudo apt install wget jq # Ubuntu / Debian
sudo yum install wget jq # CentOS / RHEL
brew install wget jq # macOS (Homebrew)
4. Wayback Machine からデータを取得する方法
(1) Wayback Machine API からスナップショット一覧を取得
まず、Wayback Machine に保存されている https://www.gamecity.ne.jp/nol/world/ 以下のスナップショットを取得します。
curl "http://web.archive.org/cdx/search/cdx?url=www.gamecity.ne.jp/nol/world/*&output=json" > snapshots.json
これで、過去のスナップショットのリストが snapshots.json に保存されます。
(2) wget でスナップショットごとにデータを取得
以下のスクリプトを実行すると、スナップショットの日付ごとにフォルダを作成し、リンクをたどりながらデータをダウンロードできます。
📌 download_nol.sh(スクリプト)
sh
#!/bin/bash
# URLのベース
BASE_URL="https://www.gamecity.ne.jp/nol/world/"
# 保存ディレクトリのベース
SAVE_ROOT="snapshots"
# Wayback Machine のスナップショットを取得
ARCHIVES=$(curl -s "http://web.archive.org/cdx/search/cdx?url=${BASE_URL}*&output=json" | jq -r '.[1:] | map([.[1], .[2]]) | .[] | @csv')
# 各スナップショットをダウンロード
while IFS=, read -r TIMESTAMP URL; do
TIMESTAMP=$(echo $TIMESTAMP | tr -d '"') # 余計なダブルクォートを削除
URL=$(echo $URL | tr -d '"')
# 保存先ディレクトリ(例: snapshots/20240101/)
SAVE_DIR="${SAVE_ROOT}/${TIMESTAMP}/"
# すでにフォルダが存在している場合はスキップ
if [ -d "$SAVE_DIR" ]; then
echo "Skipping already downloaded snapshot: $SAVE_DIR"
continue
fi
# フォルダを作成
mkdir -p "$SAVE_DIR"
# Wayback Machine のスナップショット URL
SNAPSHOT_URL="https://web.archive.org/web/${TIMESTAMP}/${URL}"
echo "Downloading: $SNAPSHOT_URL → $SAVE_DIR"
# `wget` を使ってリンク先も再帰的にダウンロード
wget -r -np -N -k -p -l 5 --convert-links --restrict-file-names=windows --no-parent --domains=web.archive.org --no-host-directories -P "$SAVE_DIR" "$SNAPSHOT_URL"
done <<< "$ARCHIVES"📌 スクリプトの使い方
- スクリプトを作成
nano download_nol.shそして、上記のコードを貼り付けて保存。 - 実行権限を付与
chmod +x download_nol.sh - スクリプトを実行
./download_nol.sh
5. ダウンロードした .html のリンクを相対パスに変換
取得した .html ファイル内の絶対リンクを 相対パスに変換 するスクリプトを実行します。
📌 convert_links_to_relative.sh
sh
#!/bin/bash
# 保存先のルートディレクトリ
SAVE_ROOT="snapshots"
# すべての .html ファイルを処理
find "$SAVE_ROOT" -type f -name "*.html" | while read -r FILE; do
echo "Processing: $FILE"
# 絶対パスを相対パスに変換
sed -i -E 's|https?://www\.gamecity\.ne\.jp/nol/world/|../|g' "$FILE"
# Wayback Machine のURLも削除(不要なプレフィックスを取り除く)
sed -i -E 's|https?://web\.archive\.org/web/[0-9]+/||g' "$FILE"
done
echo "All HTML files have been processed and converted to relative paths."📌 実行手順
- スクリプトを作成
nano convert_links_to_relative.shそして、上記のコードを貼り付けて保存。 - 実行権限を付与
chmod +x convert_links_to_relative.sh - スクリプトを実行
./convert_links_to_relative.sh
6. まとめ
📝 実行手順
wgetとjqをインストール- Wayback Machine のスナップショット一覧を取得
curl "http://web.archive.org/cdx/search/cdx?url=www.gamecity.ne.jp/nol/world/*&output=json" > snapshots.json - スクリプト
download_nol.shを実行し、データを取得./download_nol.sh - リンクを相対パスに変更
./convert_links_to_relative.sh
📂 実行後のフォルダ構成例
snapshots/
├── 20240101/ # 2024年1月1日のスナップショット
│ ├── index.html
│ ├── page1.html
│ ├── images/
│ └── styles/
├── 20230115/ # 2023年1月15日のスナップショット
│ ├── index.html
│ ├── ...
└── ...
🎯 これで、Wayback Machine に保存されている https://www.gamecity.ne.jp/nol/world/ 以下のすべてのデータを日付ごとに整理し、リンクを相対パスに変換してローカルでオフライン閲覧できるようになります! 🚀